Abstract
As podcasting has moved from a niche audio format into a mainstream channel for interviews, journalism, education, expert analysis and cultural discussion, it has created a paradox: podcasts are increasingly rich in knowledge, but still poor in navigability.
Users cannot easily search for a specific idea, skim an episode's structure, cite a precise moment or reuse podcast knowledge without listening linearly. This blog argues that AI can unlock this "audio black box" by transforming podcasts from linear audio files into searchable knowledge objects through three steps: transcription makes speech machine-readable and attributable; semantic chunking and vector search make ideas findable; and retrieval-augmented summarisation makes podcast knowledge usable.
Yet this transformation creates three ethical risks: AI may misrepresent what was said, shape which creators become visible, and extract value from creators without returning attention or revenue. Responsible podcast AI should therefore be designed as a bridge back to original listening, not as a platform-controlled substitute for it. AI should unlock podcast knowledge, not extract it.
1. Introduction: Podcast Knowledge Is Trapped in Audio
1.1 Opening Story: The Student Who Cannot Find the Argument
Think of a moment when you remember an idea from a podcast, but not where it appeared. A student writing an essay may remember that a guest gave exactly the explanation she needs in a podcast, but the episode is almost two hours long. She knows the answer is somewhere in the conversation, yet she has no index, no headings and no way to Ctrl-F the audio. The knowledge is there, but for practical purposes, it is hidden.
This is the central weakness of podcasting as a knowledge medium: podcasts are rich in ideas, but poor in navigability. Unlike articles with headings and searchable paragraphs, a podcast episode is often just a progress bar. The listener can move forward or backward, but cannot easily see the intellectual structure of the conversation.
1.2 The Central Problem: Podcasts Are Audio Black Boxes
Podcasts' value lies in long-form conversation: tone, hesitation, disagreement and context can all be preserved in ways that short-form media often lose. Yet this strength is also the source of the problem. A one-hour podcast is usually presented as a single linear audio file. Users cannot easily search inside it, skim its structure, cite a precise moment or reuse its ideas. So the problem is not content scarcity, but retrievability.
The black-box problem also affects creators and platforms. Creators may publish valuable conversations, but platforms often see only a title, a short description and a few tags. Students and journalists may want to cite a claim, but they need a reliable timestamp and transcript. The knowledge is present, but it is not machine-readable, searchable or accountable.
1.3 The AI Transformation: From Audio Object to Knowledge Object
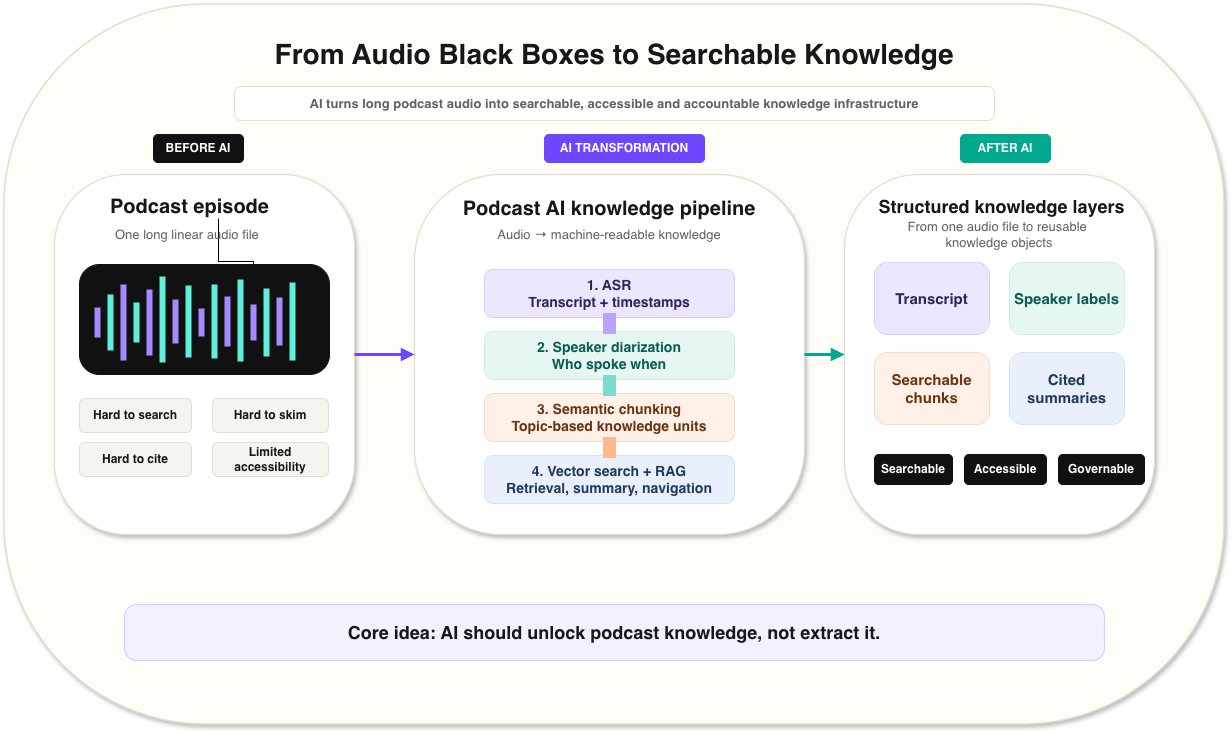
AI changes the status of a podcast. It can turn a podcast from a linear audio object into a structured knowledge object. As Figure 1 shows, the basic pipeline is: automatic speech recognition converts speech into a time-aligned transcript; speaker diarization estimates which speaker or speaker cluster spoke when; semantic chunking divides the transcript into meaningful units; embeddings and vector search make those units findable; and retrieval-augmented generation produces summaries, answers and recommendations grounded in the original audio evidence.
Figure 1. The podcast AI pipeline from audio object to searchable knowledge object
The diagram summarises how podcast AI transforms raw audio into searchable knowledge through ASR transcription, speaker diarization, semantic chunking, vector search and grounded outputs such as answers, summaries and recommendations. The governance layer underneath the pipeline highlights that confidence labels, timestamp evidence, creator controls, fairness audits and revenue attribution should be built into each technical stage rather than added afterwards.
This transformation matters because it changes what users can do. Instead of remembering the title, guest or exact wording, a user can search for the idea itself. Instead of listening linearly for three hours, a user can jump to the segment where the argument appears. The goal is not to remove listening, but to make listening easier to enter, verify and return to.
1.4 The Central Ethical Tension
The key question is not only what AI can do for podcasting, but who benefits when AI controls how podcast knowledge is accessed.
If AI produces transcripts, it affects accessibility. If AI generates summaries, it affects meaning. If AI recommends episodes, it affects visibility. If AI turns a podcast library into a conversational question-answering system, it affects monetisation. A podcast AI system may look like a simple convenience feature, but it can become a new gatekeeper between creators and audiences. This blog therefore argues for responsible podcast AI: AI should unlock knowledge without replacing, distorting or exploiting the original act of listening.
1.5 Roadmap of the Blog
As Figure 2 shows, the remainder of the blog proceeds in four stages. Section 2 introduces podcasting as a mainstream knowledge medium and explains the access, discovery and governance challenges that make AI adoption attractive. Section 3 explains the technical pipeline that turns audio into searchable knowledge: transcription, semantic search and grounded summarisation. Section 4 examines the ethical implications, focusing on accuracy, fairness and ownership. Section 5 concludes by arguing that the future of podcast AI should be symbiotic rather than parasitic.
Figure 2. Roadmap of the blog
The figure summarises the central argument of this blog: AI can transform a podcast from one long, difficult-to-search audio file into structured knowledge layers. The key design principle is that AI should guide users back to original listening rather than extract value from the podcast.
2. Domain and Challenges
2.1 Podcasting as a Mainstream Knowledge Medium
2.1.1 Introduction of Podcast
A podcast is usually understood as an episodic audio programme distributed through podcast apps, streaming platforms, RSS feeds or video platforms. In practice, the definition has widened, as many audiences now also treat video interviews on YouTube or Spotify as podcasts. The format is flexible: it can contain journalism, education, expert interviews, business analysis, comedy, cultural discussion or technical tutorials. This flexibility makes podcasting valuable for knowledge dissemination, because it preserves long-form explanation, voice, tone and interpersonal exchange.
For knowledge work, this is both powerful and awkward. The medium fits daily life because it can be consumed while walking, commuting or doing routine work. But it does not fit search very well. A user can absorb a long conversation and later struggle to retrieve the exact argument. The podcast is therefore a mainstream knowledge medium with a serious retrieval problem.
2.1.2 The Scale of the Industry
The scale of podcasting shows why this problem matters. As Figure 3 shows, Edison Research reported in The Podcast Consumer 2025 that 73% of Americans aged 12 or older had ever consumed a podcast, 55% had consumed one in the last month, and 40% had consumed one in the last week [1]. The same report estimated that total time spent with podcasts among Americans aged 13 or older had grown to 773 million hours per week [1]. Globally, DataReportal reported that 22.1% of online adults listened to at least one podcast each week in 2025 [2]. These figures are not directly comparable because they measure different populations and behaviours, but together they show the scale of podcast use.
Podcast use is now widespread enough that podcast search is no longer a niche usability problem. It is an infrastructure problem for a large-scale knowledge medium. YouTube also announced in 2025 that it had more than one billion monthly active viewers of podcast content, showing how video platforms have become part of the podcast ecosystem [3].
The commercial market has grown as well. According to the IAB/PwC Internet Advertising Revenue Report: Full Year 2025, U.S. podcast advertising revenue reached $2.9 billion in 2025 [4]. These numbers are measured differently across audio podcasts, video podcasts and streaming talk shows, but they point in the same direction: podcasting is no longer a niche format. It is a large media and knowledge industry.
Figure 3. Podcasting is now a mainstream knowledge medium
The first three bars show U.S. podcast adoption among people aged 12 or older: 73% had ever consumed a podcast, 55% had consumed one in the last month, and 40% had consumed one in the last week. The final bar shows DataReportal's global figure that 22.1% of online adults listened to at least one podcast each week in 2025 [1] [2]. Because these measures use different populations, the bars should be read as adoption signals rather than as directly comparable survey results.
2.2 Three Bottlenecks in Podcast Knowledge Access
Podcasting is changing from a casual audio format into a searchable and platform-mediated knowledge environment. This change creates three main bottlenecks:
Users cannot easily search, skim or cite specific ideas inside long episodes.
Creators with valuable knowledge may remain invisible because metadata is too thin.
Platforms struggle to moderate or recommend long audio at the relevant segment level.
2.2.1 Access Challenge: Users Cannot Search, Skim or Cite Podcasts
For users, the problem is not that podcasts are uninformative; it is that their information is difficult to access without listening linearly. This problem has three dimensions:
2.2.1.1 Searchability Problem
Users cannot easily search and locate ideas inside long episodes. If a listener wants a five-minute discussion of climate policy inside a three-hour interview, the title and description may not help.
This is a semantic problem, not only a text problem. The speaker may also use different words from the user's query. A search for "carbon tax" may miss a segment where the guest says "set a price for emissions". Even if a transcript exists, the transcript may still be too long. Good podcast search should retrieve ideas, arguments and moments, not only whole episodes.
2.2.1.2 Skimming Problem
Users also cannot quickly judge whether an episode is worth listening to. Podcasts usually only have titles and progress bars, which makes the cost of evaluation high. A student may need only one valuable argument, but must invest a large amount of time before knowing whether the episode contains it.
2.2.1.3 Citation Problem
Students, journalists and researchers need precise references. A written source can be cited by page, paragraph or section. A podcast needs an episode title, date, speaker and timestamp. Without a reliable transcript and timestamp, it is difficult to quote accurately or verify context.
2.2.2 Discovery Challenge: Creators Are Hard to Find Without Rich Metadata
Without richer semantic metadata, creators with valuable knowledge may remain invisible simply because platforms cannot understand what their episodes contain, for the following reasons:
2.2.2.1 Metadata Is Too Thin
Titles and descriptions cannot represent a two-hour conversation. A podcast episode may begin with a personal story, move into economic policy, discuss public health, and finish with cultural commentary. Thin metadata hurts creators because it hides their real value. Spotify research has studied the use of semantic information to recommend underserved podcasts and reduce rich-get-richer effects in discovery [5]. This shows that semantic metadata is not just a technical convenience; it can affect whose voices become visible.
2.2.2.2 Cold-Start Problem
New creators lack listening history and platform signals. Popular creators already have downloads, ratings, shares and user behaviour data. New creators often do not. If platforms depend heavily on popularity signals, they may repeatedly recommend already successful shows. Semantic understanding can partly address this problem by recommending content because of what it contains, not only because the creator is already famous.
2.2.3 Governance Challenge: Platforms Cannot Easily Moderate or Recommend
2.2.3.1 Moderation Problem
Harmful claims may appear in specific minutes. A two-hour podcast can be mostly harmless but contain one defamatory statement, one health misinformation claim, one copyrighted music clip or one hateful remark. Episode-level moderation is too blunt so it may miss harmful segments. Long audio is therefore a potential blind spot for platform governance.
2.2.3.2 Recommendation Problem
Episode-level recommendation is less precise than segment-level relevance. A user may not want the whole episode; they may want the ten-minute part that matches their interest. Segment-level recommendation can connect users to relevant moments across different episodes, but it also gives platforms more power to decide which segments count as relevant.
2.3 The Case for AI Adoption
Manual tagging cannot scale to modern podcasting. Human transcription is useful, but expensive and time-consuming. Manual chapter writing is valuable, but many independent creators do not have the resources to do it. As podcast libraries grow, the only practical way to convert raw, unstructured audio into searchable knowledge is to use AI and machine learning.
This shift is already visible in mainstream products. Apple introduced transcripts for Apple Podcasts with iOS 17.4, making podcast audio readable and searchable across many countries and regions [6]. Spotify now supports transcript management, automatic episode chapters and natural-language podcast discovery features [7] [8] [9]. These examples show that AI transcription and semantic navigation are becoming ordinary podcast infrastructure rather than experimental add-ons.
The case for AI adoption is therefore strong. AI can decode speech into text, structure long conversations, support semantic search, improve accessibility, generate summaries and make creators easier to discover. But the case for adoption is not the same as the case for unrestricted deployment. AI solves the audio black-box problem only if it is designed to preserve accuracy, fairness and creator value.
3. Applications of AI Technologies: Three Steps from Audio to Searchable Knowledge
The most important AI transformation in podcasting can be understood through three technical functions: AI decodes speech into text, structures long transcripts into searchable knowledge units, and mediates access through summaries, question-answering and recommendations.
Figure 4. Technical pipeline as a knowledge flow
The Sankey diagram shows how one audio file branches into transcript evidence, search, summaries and recommendations.
3.1 Transcription: Making Podcast Audio Machine-Readable
Before a podcast can be searched, summarised or cited, the speech must be converted into machine-readable text. Podcast audio is difficult because episodes may contain background noise, laughter, interruptions, music, accents, informal language, specialist terms and multiple speakers.
3.1.1 Automatic Speech Recognition: From Waveform to Transcript
Automatic Speech Recognition, or ASR, converts acoustic signals into text. A modern ASR pipeline usually begins with an audio waveform, extracts acoustic representations and uses a neural model to predict text tokens. Older systems often separated acoustic modelling, pronunciation modelling and language modelling. Modern systems increasingly use end-to-end neural architectures, including Transformer-based sequence-to-sequence models.
Whisper is an important example. The Whisper paper studies speech recognition systems trained on large amounts of weakly supervised multilingual audio from the web, and the model is widely used because it is robust across tasks and languages [10]. For podcasts, this robustness matters because episodes often contain casual speech, domain-specific vocabulary and varied recording conditions.
wav2vec 2.0 is another influential approach. It learns speech representations from raw audio through self-supervised learning and can then be fine-tuned for speech recognition with less labelled data [11]. This is important for podcasting because podcast content includes many languages, accents, informal speech styles and specialist domains where large labelled datasets may not exist. Self-supervised speech models therefore help make transcription more scalable across diverse podcast libraries.
These research advances also explain why transcription is moving from a specialist post-production service to a platform-level capability. Systems such as Whisper and wav2vec 2.0 demonstrate the technical feasibility of robust automatic transcription, while commercial speech-to-text services, including OpenAI's newer models, show how this capability can now be integrated into podcast platforms, search tools and creator workflows [12].
3.1.2 Speaker Diarization: Who Spoke When?
Speaker diarization answers the question: which speaker or speaker cluster spoke when; real-world speaker names may still require metadata or human confirmation. In a podcast conversation, meaning depends on speaker attribution. A claim made by the guest is different from a challenge made by the host. A joke may be understandable only because of who said it and how another speaker responded.
A typical diarization system detects speech activity, segments the audio, extracts speaker embeddings and clusters segments that appear to belong to the same speaker. pyannote.audio is a widely used open-source toolkit for speaker diarization, including speaker segmentation, neural speaker embedding and clustering [13]. Diarization is technically important because a correct sentence assigned to the wrong speaker is still a serious error.
For podcast AI, the output of transcription should therefore be structured data, not just text:
episode_id,segment_id,speaker_id,start_time,end_time,transcript_text,confidence
This structure becomes the foundation for all later stages: search, summarisation, recommendation, citation and moderation. Apple researchers have argued that simple word error rate is not enough to evaluate transcript quality, because some errors matter more than others for readability and accessibility [14]. For podcast knowledge, misrecognising a filler word is minor; misrecognising a person's name, a medical term or a policy condition may change the meaning of the whole passage.
3.2 Semantic Search: Making Podcast Knowledge Findable
Structuring makes podcast knowledge navigable. Users no longer need to know the title, guest or exact wording, because they can search for the idea itself.
3.2.1 Semantic Chunking: The Length Problem after Transcription
The length problem does not disappear after transcription. A two-hour podcast transcript may still be tens of thousands of words long. A user cannot reasonably read the entire transcript just to find one argument. The transcript must be divided into meaningful units.
Semantic chunking means splitting the transcript into coherent segments: a question and answer, a topic shift, an explanation, an argument, a story or a chapter. Podcast conversations are spontaneous. Speakers interrupt each other, return to earlier points and move gradually between topics. A useful chunk should preserve enough context for meaning while remaining short enough to retrieve and cite.
Recent work on podcast chapterisation addresses this problem directly. PODTILE divides long podcast transcripts into semantically coherent chapters with titles and timestamps, noting that podcast transcripts are often lengthy and less structured than written text [15]. This is exactly the skimming problem in technical form: the user needs a map of the conversation.
3.2.2 Embeddings and Vector Search: Searching Meaning Rather than Exact Words
The core of semantic search is searching meaning rather than exact words. When a user searches for "carbon tax", the guest might say "set a price for emissions". Traditional keyword search may not find this segment, but embedding-based retrieval can.
An embedding is a numerical representation of meaning. A model converts a text segment into a vector in a high-dimensional space. Semantically similar segments are placed near each other. Sentence-BERT is an important early model for producing semantically meaningful sentence embeddings [16]. More recent benchmarks such as MTEB evaluate embedding models across many retrieval and classification tasks [17]. Spotify's engineering work on natural language search describes the same principle: semantic search matches a query and document that are meaningfully related, even without exact word overlap [18].
At scale, vector search requires efficient indexing. Systems such as FAISS and Milvus support large-scale nearest-neighbour retrieval and vector data management, which are necessary for searching across large podcast libraries [19] [20]. Figure 5 shows how this could appear to a user. The important design point is that search should return a timestamped segment, speaker label, transcript snippet and play button, not only an AI-generated answer.
Figure 5. Segment-level semantic search interface for podcast knowledge
The mock interface shows how podcast AI can retrieve meaning rather than only exact keywords. A query about carbon tax returns timestamped transcript segments with speaker or chapter labels, short contextual snippets and playback actions. This design supports the main argument of the blog: podcast AI should help users find relevant moments and then return to the original audio for verification, rather than replacing listening with unsupported AI answers.
The guest discusses pricing emissions, redistribution to households and protecting low-income groups.
Play from 01:14:22The host asks whether visible fuel prices make carbon policy unpopular even when rebates exist.
Play from 01:17:06Additionally, the same transcript-and-chunk pipeline can also support segment-level moderation. Instead of judging a two-hour episode as a whole, platforms can classify timestamped segments for policy-relevant categories such as hate speech, health misinformation or copyright-sensitive audio. This addresses one of the governance challenges introduced earlier: harmful or policy-sensitive content may appear only in specific minutes of a long episode.
3.3 Grounded Summarisation: Making Podcast Knowledge Usable
While search helps users find relevant segments, summarisation helps users understand what those segments mean. But podcast summarisation must be grounded, because a fluent summary can easily distort a complex conversation.
3.3.1 Retrieval-Augmented Generation
Retrieval-Augmented Generation, or RAG, combines a generative language model with retrieved external evidence. In the original RAG formulation, a model retrieves relevant passages from a dense vector index and then generates an answer conditioned on those passages [21]. For podcasts, the external evidence is the timestamped transcript of the original audio.
A podcast RAG system works in four steps. First, the user's question is embedded. Second, the system retrieves relevant transcript chunks. Third, the language model generates an answer using those chunks. Fourth, the answer cites the episode, speaker and timestamp that support it. This structure is important because large language models can hallucinate: they may generate fluent text that is unsupported or inaccurate [22]. RAG does not eliminate hallucination; it makes hallucination easier to detect because important claims can be checked against retrieved transcript evidence.
Figure 6. Why podcast RAG should cite audio evidence
Grounding changes a summary from a standalone claim into a navigational layer back to the original conversation.
A responsible podcast Q&A system should not simply answer the user; it should show which transcript segment and timestamp support the answer. The principle should be simple: no timestamp, no trust. The following illustrative example shows why timestamped evidence matters. Suppose a user asks a podcast AI system about a policy discussion:
User query: What did the guest say about carbon taxes?
Retrieved evidence: Episode transcript, Guest A, 01:14:22-01:17:05. The retrieved segment discusses pricing emissions, redistributing revenue to households and protecting low-income groups.
Weak AI answer: The guest supports carbon taxes.
Better AI answer: The guest supports carbon taxes conditionally. They argue that carbon taxes can work if revenue is redistributed to households and if low-income groups are protected.
User action: The interface should provide a "play from 01:14:22" button and a transcript link so that the user can verify the context.
The weak answer is not completely false, but it removes the condition that makes the argument meaningful. The better answer preserves nuance, cites the relevant moment and gives the user a path back to the original audio. Recent work such as VoxRAG also explores transcription-free audio retrieval, where systems retrieve relevant audio segments directly from spoken queries [23]. This is promising, but text transcripts remain important for accountability because users and creators need visible evidence.
3.3.2 LLM Summarisation and Recommendation
The final layer of the pipeline is LLM-based summarisation and recommendation. This is not simply a matter of sending a whole podcast transcript to a language model and asking for a summary. A more reliable design is a retrieval-grounded pipeline. The system first uses the transcript structure created earlier: speaker labels, timestamps and semantic chunks. Each chunk is converted into an embedding and stored in a vector index or vector database such as FAISS or Milvus [19] [20]. When a user asks a question or requests a summary, the system retrieves the most relevant transcript chunks and passes them to an LLM as evidence.
In practice, this kind of system can be built with RAG orchestration frameworks such as LangChain or LlamaIndex. LangChain describes retrieval as a way of fetching relevant external knowledge at query time and using it as the foundation for RAG, while LlamaIndex similarly frames RAG as a process in which data is indexed, relevant context is retrieved, and that context is passed to the LLM with the user's query [24] [25]. For podcasts, the indexed data would be timestamped transcript chunks rather than web pages or PDFs. A simplified pipeline would therefore look like this: transcript chunks are embedded, stored in a vector database, retrieved according to the user's query, and then synthesised by an LLM into a summary, answer or recommendation.
This technical design is useful because it supports both summarisation and recommendation. For summarisation, the system can use hierarchical summarisation: short transcript chunks are first summarised with their speaker labels and timestamps, then combined into chapter-level or episode-level summaries. For recommendation, the same embeddings can represent the meaning of podcast segments. Instead of recommending only whole shows based on popularity, the platform can compare a user's query or listening history with segment embeddings and ask: "which segment explains the idea this user is looking for?" This could benefit small or niche creators, because their content may be surfaced through meaning rather than existing audience size [5] [18].
4. Ethical Implications and Responsible Design: Who Controls AI-Mediated Podcast Knowledge?
Can AI represent what was said?
Transcription, speaker attribution, retrieval and summarisation errors can all distort the original conversation.
Who decides which voices are heard?
AI discovery may help niche creators, but it may also favour popular shows and machine-friendly speech.
Does AI unlock or replace listening?
AI answers may capture attention and value without returning listens, revenue or control to creators.
4.1 Accuracy and Trust: Can AI Accurately Represent What Was Said?
The first ethical issue is accuracy and trust. Podcast AI can fail at several levels: transcription, speaker attribution, retrieval and summarisation. Each failure changes how users understand the original conversation.
4.1.1 Transcription Errors Affect Access and Meaning
Transcription errors affect both access and meaning. Accents, dialects, background noise and overlapping speech can all reduce ASR accuracy, but these errors are not evenly distributed across speakers. Koenecke et al.'s study of five commercial ASR systems found substantial racial disparities in word error rates: in their tested U.S. speech samples, the systems produced higher average error rates when transcribing Black speakers than white speakers [26]. This disparity should be understood as a limitation of ASR systems and their training data, not as a deficiency of speakers. For podcasting, the consequence is serious: if some speakers are transcribed less accurately, their contributions may become less searchable, less quotable and less visible.
4.1.2 The Risk of Over-Summary
The AI summary might take things out of context. If a complex discussion is compressed into three sentences, the original tone, reserved opinions and rebuttal relationships may disappear. This is especially dangerous because users may trust a summary without checking the original audio.
Original: Carbon taxes can work if revenue is redistributed to households.
Misleading summary: The guest supports carbon taxes.
The summary is not completely false, but it removes the condition that makes the argument meaningful. In political, scientific or medical discussions, this difference can be very important. A responsible system should therefore mark the difference between direct quotation, close paraphrase and generated interpretation.
4.1.3 Speaker Attribution Errors Affect Accountability
Speaker attribution errors affect accountability. A correct sentence assigned to the wrong speaker is still a serious error. In podcasts, the speaker relationship often carries the meaning. The host may challenge a claim, the guest may qualify it, and another guest may disagree. If the system assigns these turns incorrectly, the transcript misrepresents the conversation.
4.1.4 Responsible Design: Evidence-Based Summaries
Responsible podcast AI should be built around evidence-based summaries. Every important AI-generated claim should link back to the original timestamp. No timestamp, no trust.
- Timestamp citation and transcript evidence: important claims should cite the supporting transcript segment and provide a play button for the original audio.
- Uncertainty labels: if transcript confidence is low or retrieval evidence is weak, the system should say so.
- Creator control: transcript generation should be opt-out or editable, and AI summaries should be reviewable where they represent the creator's work.
4.2 Fairness and Visibility: Who Decides Whose Voices Are Heard?
The second ethical issue is fairness. AI discovery may help users find niche creators, but it may also reinforce inequality if the system favours content that is easier to transcribe, classify and summarise.
4.2.1 AI Discovery May Also Reinforce Inequality
If recommendation systems reward content that is easy to transcribe, summarise and classify, they may favour creators who speak in structured, standardised and machine-readable ways. Creators with regional accents, multilingual speech, noisy recording environments or informal conversational styles may become less visible.
AI discovery therefore has two sides. It can reduce the cold-start problem by understanding content semantically. But it can also create a new form of algorithmic inequality. Fair podcast AI should not only optimise what users like; it should also consider whose voices become discoverable.
4.2.2 Responsible Design: Explainable Recommendation and Appeal
Responsible design should include explainable recommendation and appeal mechanisms. Creators should be able to see how their content is represented by the system: detected topics, indexed segments, transcript confidence, moderation flags and recommendation exposure. Without such information, creators are judged by a black-box system they cannot inspect.
Platforms should also provide appeal mechanisms. If a creator believes a transcript, topic label, moderation decision or ranking signal is wrong, they should have a way to challenge it. Fairness is not achieved by claiming that the algorithm is neutral. It is achieved by making the system inspectable, correctable and accountable.
4.3 Ownership and Value Extraction: Does AI Replace Listening?
The third ethical issue is ownership and value extraction. AI makes podcast knowledge more accessible, but if users no longer listen to the original programmes, do creators lose their value instead?
4.3.1 The Zero-Click Consumption Problem
Zero-click experiences are already discussed in web search, where users receive answers directly from the search interface rather than visiting the original publisher. Bain has argued that AI-driven zero-click search changes marketing and discovery because users may no longer click through to the original source [27]. By analogy with zero-click search, podcast AI could create a similar zero-click listening problem: Users may get the knowledge without listening to the source. For example, a RAG-powered "chat with podcasts" interface could give users the key takeaways without requiring them to play the episode. This is convenient for users, but it creates a zero-click consumption problem.
If the platform turns the podcast library into a RAG-powered answer engine, users may directly obtain key points through Q&A and AI summaries, thereby skipping the original programme, reducing listens, watch-time and ad revenue. A good AI summary should help users decide where to listen; a bad AI summary becomes a substitute that extracts the value of listening while bypassing the creator.
4.3.2 Creator Value and Platform Capture
The creator produces the knowledge, but the AI interface captures the attention. They may lose listens, completion rates and advertising revenue as AI becomes a value extractor.
This raises a basic question: who should profit when AI turns a creator's long-form conversation into instant answers? If a platform uses a podcast episode to answer a user's question, the platform benefits from the creator's labour. If the AI interface captures the user's attention without returning value to the people who produced the episode, then attribution alone is not enough.
The issue is connected to wider debates about publisher control over AI summaries. In 2026, reporting on the UK Competition and Markets Authority described proposed measures requiring more meaningful publisher choice over whether content is used in AI-generated summaries in Google Search [28]. Podcasts face a parallel question. Creators need meaningful control over whether their work is indexed, summarised, used for Q&A or used for model training.
4.3.3 Responsible Design: Granular Consent and Revenue Sharing
Platforms should offer granular consent options to creators. Permission should not be treated as a single yes-or-no decision, because different AI uses create different levels of risk and value extraction. At minimum, creators should be able to distinguish between four forms of AI use:
- Training: using podcast audio or transcripts to train, fine-tune or improve AI models.
- Indexing: storing transcripts, metadata or embeddings so that episodes and segments can appear in search results.
- Summarisation: generating show notes, chapter titles, previews or learning notes from the transcript.
- Question-answering: allowing users to ask an AI system questions that are answered from the episode without necessarily playing the original audio.
The permissions should be separated rather than bundled together. For example, a creator may allow accessibility transcripts and search indexing, but reject model training. Another creator may allow short chapter summaries, but reject full conversational Q&A features that could substitute for listening. The platform interface should make these choices visible, reversible and understandable. It should also specify whether creators receive attribution, playback traffic or revenue when AI-generated answers are based on their work.
Copyright law already recognises that creators have rights over the expression of their original works, including copying, distribution, adaptation and public communication [29] [30]. However, copyright does not straightforwardly solve every AI podcast question, because an AI answer may extract facts, themes or arguments rather than reproduce a long passage verbatim. This is why podcast AI governance should not rely on copyright alone. It also needs consent, attribution, provenance and fair value-sharing mechanisms. Podcast AI needs a similar norm for knowledge provenance: which episode supported this answer, whose voice was used, and what value flowed back? If AI interfaces monetise podcast knowledge, attribution alone is not enough; creators need control over use and a fair share of the value created from their work.
4.4 Summary of the Ethics-to-Responsible Design Mapping
Three risks require three responses: accuracy requires evidence; fairness requires explainability; ownership requires consent and compensation. Table 1 summarises this mapping.
| Ethical risk | Main danger | Governance response |
|---|---|---|
| Accuracy and trust | AI summaries distort nuance or assign claims to the wrong speaker. | Timestamp citation, transcript evidence, uncertainty labels and editable transcripts. |
| Fairness and visibility | Algorithms decide who is heard, often favouring already popular or machine-friendly speech. | Explainable recommendation, creator dashboards, exposure metrics and appeal mechanisms. |
| Ownership and value extraction | AI answers replace listening while platforms capture value from creator knowledge. | Granular consent, separate permissions, attribution, playback links and revenue sharing. |
5. Conclusion: Unlock Podcast Knowledge, Not Extract It
5.1 Summary of the AI Transformation
Podcasting matters because it preserves forms of knowledge that short-form media often lose: long explanation, human voice, disagreement, uncertainty and trust. But these same qualities make podcasts hard to navigate. The audio black box limits search, access and discovery.
AI creates a knowledge pipeline: decode, structure and mediate. The first step is decoding. ASR and diarization turn speech into attributed, timestamped text. The second step is structuring. Semantic chunking, embeddings and vector search turn long transcripts into searchable knowledge units. The third step is mediation. RAG, summaries and recommendations help users ask questions, preview content and jump to relevant moments. Together, these technologies can make podcasts more useful as knowledge sources.
5.2 The Crucial Choice: Parasitic Extraction vs. Symbiotic Ecosystem
In a parasitic system, platforms turn creators' voices into unpaid infrastructure for automated answers. Users receive convenient summaries, but creators lose attention, revenue and control. The podcast becomes raw material for platform-controlled knowledge extraction.
In a symbiotic ecosystem, AI helps people find, understand and return to human conversations. Transcripts are editable. Summaries cite timestamps. Recommendations are explainable. Creators can control AI uses of their work. Revenue flows back when AI interfaces monetise creator knowledge.
The argument of this blog is therefore simple: AI should make podcast listening more searchable, inclusive and rewarding, but it should not turn creators' work into free raw material for platform-controlled knowledge extraction.
References
- Edison Research. (2025). The Podcast Consumer 2025. Available at: https://www.edisonresearch.com/the-podcast-consumer-2025/ [Accessed 1 May 2026].
- DataReportal. (2025). Digital 2025: Podcasts gaining popularity. Available at: https://datareportal.com/reports/digital-2025-sub-section-podcasts-gain-popularity [Accessed 1 May 2026].
- YouTube. (2025). Celebrating 1 billion monthly podcast users on YouTube. Available at: https://blog.youtube/news-and-events/1-billion-monthly-podcast-users/ [Accessed 1 May 2026].
- Interactive Advertising Bureau and PwC. (2026). Internet Advertising Revenue Report: Full Year 2025. Available at: https://www.iab.com/insights/internet-advertising-revenue-report-full-year-2025/ [Accessed 1 May 2026].
- Aziz, M., Wang, A., Pappu, A., Bouchard, H., Zhao, Y., Carterette, B. and Lalmas, M. (2021). Leveraging semantic information to facilitate the discovery of underserved podcasts. Proceedings of the 30th ACM International Conference on Information & Knowledge Management. Available at: https://research.atspotify.com/publications/leveraging-semantic-information-to-facilitate-the-discovery-of-underserved-podcasts [Accessed 1 May 2026].
- Apple. (2024). Transcripts on Apple Podcasts. Available at: https://podcasters.apple.com/support/5316-transcripts-on-apple-podcasts [Accessed 1 May 2026].
- Spotify. (n.d.). Managing episode transcripts on Spotify. Available at: https://support.spotify.com/us/creators/article/managing-episode-transcripts-on-spotify/ [Accessed 1 May 2026].
- Spotify. (n.d.). Episode chapters. Available at: https://support.spotify.com/us/creators/article/episode-chapters/ [Accessed 1 May 2026].
- Spotify. (2026). Prompted Playlist levels up to include podcasts. Available at: https://newsroom.spotify.com/2026-04-07/prompted-playlist-for-podcasts-launch/ [Accessed 1 May 2026].
- Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C. and Sutskever, I. (2023). Robust speech recognition via large-scale weak supervision. Proceedings of the 40th International Conference on Machine Learning. Available at: https://proceedings.mlr.press/v202/radford23a.html [Accessed 1 May 2026].
- Baevski, A., Zhou, H., Mohamed, A. and Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems. Available at: https://arxiv.org/abs/2006.11477 [Accessed 1 May 2026].
- OpenAI. (n.d.). Speech to text: OpenAI API documentation. Available at: https://developers.openai.com/api/docs/guides/speech-to-text [Accessed 1 May 2026].
- Bredin, H. (2023). pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. Proceedings of Interspeech 2023. Available at: https://www.isca-archive.org/interspeech_2023/bredin23_interspeech.html [Accessed 1 May 2026].
- Apple Machine Learning Research. (2024). Humanizing Word Error Rate for ASR Transcript Readability and Accessibility. Available at: https://machinelearning.apple.com/research/humanizing-wer [Accessed 1 May 2026].
- Ghazimatin, A., et al. (2024). PODTILE: Facilitating podcast episode browsing with auto-generated chapters. Available at: https://arxiv.org/abs/2410.16148 [Accessed 1 May 2026].
- Reimers, N. and Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using Siamese BERT-networks. Proceedings of EMNLP-IJCNLP. Available at: https://aclanthology.org/D19-1410/ [Accessed 1 May 2026].
- Muennighoff, N., Tazi, N., Magne, L. and Reimers, N. (2023). MTEB: Massive text embedding benchmark. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Available at: https://aclanthology.org/2023.eacl-main.148/ [Accessed 1 May 2026].
- Spotify Engineering. (2022). Introducing Natural Language Search for Podcast Episodes. Available at: https://engineering.atspotify.com/2022/03/introducing-natural-language-search-for-podcast-episodes [Accessed 1 May 2026].
- Johnson, J., Douze, M. and Jégou, H. (2017). Billion-scale similarity search with GPUs. Available at: https://arxiv.org/abs/1702.08734 [Accessed 1 May 2026].
- Wang, J., et al. (2021). Milvus: A purpose-built vector data management system. Proceedings of the 2021 International Conference on Management of Data. Available at: https://dl.acm.org/doi/10.1145/3448016.3457550 [Accessed 1 May 2026].
- Lewis, P., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems. Available at: https://arxiv.org/abs/2005.11401 [Accessed 1 May 2026].
- Huang, L., et al. (2025). A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2), Article 42, 1-55. Available at: https://dl.acm.org/doi/10.1145/3703155 [Accessed 1 May 2026].
- Rackauckas, Z. and Hirschberg, J. (2025). VoxRAG: A step toward transcription-free RAG systems in spoken question answering. Available at: https://arxiv.org/abs/2505.17326 [Accessed 1 May 2026].
- LangChain. (n.d.). Retrieval. Available at: https://docs.langchain.com/oss/python/langchain/retrieval [Accessed 1 May 2026].
- LlamaIndex. (n.d.). Introduction to RAG. Available at: https://developers.llamaindex.ai/python/framework/understanding/rag/ [Accessed 1 May 2026].
- Koenecke, A., Nam, A., Lake, E., Nudell, J., Quartey, M., Mengesha, Z., Toups, C., Rickford, J. R., Jurafsky, D. and Goel, S. (2020). Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences, 117(14), 7684-7689. Available at: https://www.pnas.org/doi/10.1073/pnas.1915768117 [Accessed 1 May 2026].
- Bain & Company. (2025). Goodbye clicks, hello AI: Zero-click search redefines marketing. Available at: https://www.bain.com/insights/goodbye-clicks-hello-ai-zero-click-search-redefines-marketing/ [Accessed 1 May 2026].
- Associated Press. (2026). UK proposes forcing Google to let publishers opt out of AI summaries. Available at: https://apnews.com/article/f2bf8545f3b987aa1900a829c0d01390 [Accessed 1 May 2026].
- World Intellectual Property Organization. (n.d.). Copyright. Available at: https://www.wipo.int/en/web/copyright [Accessed 1 May 2026].
- GOV.UK. (n.d.). How copyright protects your work. Available at: https://www.gov.uk/copyright [Accessed 1 May 2026].